[인더뉴스 정재혁 기자] 자동차사고가 발생했을 때 운전자의 과실 비율에 따라 다음해 보험료에 할인·할증율을 달리 적용해야 한다는 주장이 제기됐다. 지금까지는 과실(비율)이 많고 적음이 할증 보험료에 영향을 미치지 않아, 상대적으로 과실이 적은 운전자와 많은 운전자의 보험료 할증 부담이 비슷해 형평성 문제가 발생했다.
또한 차량을 2대 이상 보유한 가입자의 경우, 다른 차량은 본인 외의 다른 사람이 주로 운전하는데도 가입자의 할인할증 등급이 적용되는 점이 불합리하다는 지적도 나왔다. 이에 따라 다수차량 보유자에 위험도에 맞는 보험료를 부과할 수 있도록 개정해야 한다는 주장이다.
 박소정 서울대 교수는 2일 보험개발원(원장 성대규)이 개최한 ‘자동차보험 개별할인할증제도의 평가와 개선’ 공청회에서 현행 자동차보험 할증제도의 문제점을 지적하고 개선책을 제시했다.
박소정 서울대 교수는 2일 보험개발원(원장 성대규)이 개최한 ‘자동차보험 개별할인할증제도의 평가와 개선’ 공청회에서 현행 자동차보험 할증제도의 문제점을 지적하고 개선책을 제시했다.현재 자동차보험 개별할인할증 제도는 사고내용에 따라 점수가 부여되고 1년간의 사고점수·3년간 사고 유무에 따라 할인할증 등급이 부여되는 구조다.
여기에 보험사별로 사고건수요율(NCR계수: Number of Claim Rate)을 자율적으로 운영한다. 2013년 이후 보험사는 과거 3년간·과거 1년간 사고건수에 따라 보험료를 차등화하고 있다.
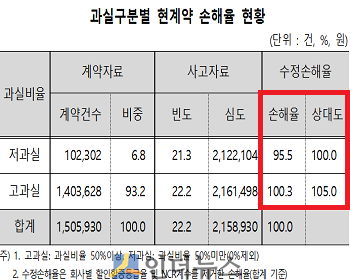
박 교수는 이러한 방식이 사고 당사자 간의 과실비율을 고려하지 않아, 고과실자(50%이상)와 저과실자(50% 미만) 사이에 보험료 할증이 동일하게 이뤄진다는 것을 문제로 지적했다. 통계 분석 결과, 과실이 많은 운전자의 손해율이 적은 운전자의 손해율보다 약 5% 높은 것으로 나타났다.
앞서 언급했듯이 현행 할인·할증구조는 과실비율이 높은 운전자와 낮은 운전자간 보험료 할증 방식이 동일해 불합리하다는 지적이 제기돼 왔다.
이에 대한 개선책으로 박 교수는 과실 50% 미만(저과실) 사고 1건을 사고점수에 제외하는 방안을 제시했다. 단, 과실이 낮더라도 무사고자와 동일하게 할인할 경우, 그 위험이 무사고자에게 전가될 수 있기 때문에 3년간 할인을 유예하는 방식이다.
자동차 다수보유자의 할인할증제도도 문제로 지적됐다. 기명 피보험자가 자동차를 추가 구입하는 경우, 다른 사람(자녀 등)이 해당 차량을 주로 운전하는 경우에도 기존 할인할증등급을 그대로 승계해 보험료를 할인받는 문제가 발생한다.
예를 들어, A씨는 16등급이고 그랜져 1대를 소유중인데, 자녀 B가 운행하기 위해 쏘나타를 추가로 구입하면서 기명피보험자를 A로 할 경우, 추가 자동차 쏘나타에도 16등급이 적용된다. 최초 가입 때 적용등급(11등급)보다 보험료가 할인되는 셈이다.
2015년 기준, 할인할증등급을 승계 받은 추가차량은 약 78만대로 나타났다. 이 차량들의 평균 할인할증등급은 16.8등급으로 11등급에 비해 약 30.5%의 보험료를 할인받았다.
박 교수는 “기명피보험자의 동일성 여부만으로 추가되는 자동차에 대해 할인할증등급이 승계되는 제도를 폐지하면 자동차를 1대만 보유한 사람에게 전가되는 보험료 부담을 해소할 수 있다”며 “단, 다수차량 보유자에게는 위험도에 맞는 보험료를 부과할 수 있도록 할인요율 신설이 필요하다”고 말했다.





![[2025 2분기 실적] 아시아나항공, 영업익 340억…흑자전환](https://www.inthenews.co.kr/data/cache/public/photos/20250833/art_17551321016342_fc3205_120x90.jpg)











